
The library provides more than 100 algorithms. Fortunately, like the containers, the algorithms have a consistent architecture. Understanding this architecture makes learning and using the algorithms easier than memorizing all 100+ of them. In this chapter, we’ll illustrate how to use the algorithms, and describe the unifying principles that characterize them. Appendix A lists all the algorithms classified by how they operate.
With only a few exceptions, the algorithms operate over a range of elements. We’ll refer to this range as the “input range.” The algorithms that take an input range always use their first two parameters to denote that range. These parameters are iterators denoting the first and one past the last elements to process.
Although most algorithms are similar in that they operate over an input range, they differ in how they use the elements in that range. The most basic way to understand the algorithms is to know whether they read elements, write elements, or rearrange the order of the elements.
A number of the algorithms read, but never write to, the elements in their input range. The find function is one such algorithm, as is the count function we used in the exercises for § 10.1 (p. 378).
Another read-only algorithm is accumulate, which is defined in the numeric header. The accumulate function takes three arguments. The first two specify a range of elements to sum. The third is an initial value for the sum. Assuming vec is a sequence of integers, the following
// sum the elements in vec starting the summation with the value 0
int sum = accumulate(vec.cbegin(), vec.cend(), 0);
sets sum equal to the sum of the elements in vec, using 0 as the starting point for the summation.
The type of the third argument to
accumulatedetermines which addition operator is used and is the type thataccumulatereturns.
The fact that accumulate uses its third argument as the starting point for the summation has an important implication: It must be possible to add the element type to the type of the sum. That is, the elements in the sequence must match or be convertible to the type of the third argument. In this example, the elements in vec might be ints, or they might be double, or long long, or any other type that can be added to an int.
As another example, because string has a + operator, we can concatenate the elements of a vector of strings by calling accumulate:
string sum = accumulate(v.cbegin(), v.cend(), string(""));
This call concatenates each element in v onto a string that starts out as the empty string. Note that we explicitly create a string as the third parameter. Passing the empty string as a string literal would be a compile-time error:
// error: no + on const char*
string sum = accumulate(v.cbegin(), v.cend(), "");
Had we passed a string literal, the type of the object used to hold the sum would be const char*. That type determines which + operator is used. Because there is no + operator for type const char*, this call will not compile.
Ordinarily it is best to use
cbegin()andcend()(§ 9.2.3, p. 334) with algorithms that read, but do not write, the elements. However, if you plan to use the iterator returned by the algorithm to change an element’s value, then you need to passbegin()andend().

Another read-only algorithm is equal, which lets us determine whether two sequences hold the same values. It compares each element from the first sequence to the corresponding element in the second. It returns true if the corresponding elements are equal, false otherwise. The algorithm takes three iterators: The first two (as usual) denote the range of elements in the first sequence; the third denotes the first element in the second sequence:
// roster2 should have at least as many elements as roster1
equal(roster1.cbegin(), roster1.cend(), roster2.cbegin());
Because equal operates in terms of iterators, we can call equal to compare elements in containers of different types. Moreover, the element types also need not be the same so long as we can use == to compare the element types. For example, roster1 could be a vector<string> and roster2 a list<const char*>.
However, equal makes one critically important assumption: It assumes that the second sequence is at least as big as the first. This algorithm potentially looks at every element in the first sequence. It assumes that there is a corresponding element for each of those elements in the second sequence.
Algorithms that take a single iterator denoting a second sequence assume that the second sequence is at least as large at the first.
Exercises Section 10.2.1
Exercise 10.3: Use
accumulateto sum the elements in avector<int>.Exercise 10.4: Assuming
vis avector<double>, what, if anything, is wrong with callingaccumulate(v.cbegin(), v.cend(), 0)?Exercise 10.5: In the call to
equalon rosters, what would happen if both rosters held C-style strings, rather than librarystrings?
Some algorithms assign new values to the elements in a sequence. When we use an algorithm that assigns to elements, we must take care to ensure that the sequence into which the algorithm writes is at least as large as the number of elements we ask the algorithm to write. Remember, algorithms do not perform container operations, so they have no way themselves to change the size of a container.
Some algorithms write to elements in the input range itself. These algorithms are not inherently dangerous because they write only as many elements as are in the specified range.
As one example, the fill algorithm takes a pair of iterators that denote a range and a third argument that is a value. fill assigns the given value to each element in the input sequence:
Some algorithms read elements from two sequences. The elements that constitute these sequences can be stored in different kinds of containers. For example, the first sequence might be stored in a
vectorand the second might be in alist, adeque, a built-in array, or some other sequence. Moreover, the element types in the two sequences are not required to match exactly. What is required is that we be able to compare elements from the two sequences. For example, in theequalalgorithm, the element types need not be identical, but we do have to be able to use==to compare elements from the two sequences.Algorithms that operate on two sequences differ as to how we pass the second sequence. Some algorithms, such as
equal, take three iterators: The first two denote the range of the first sequence, and the third iterator denotes the first element in the second sequence. Others take four iterators: The first two denote the range of elements in the first sequence, and the second two denote the range for the second sequence.Algorithms that use a single iterator to denote the second sequence assume that the second sequence is at least as large as the first. It is up to us to ensure that the algorithm will not attempt to access a nonexistent element in the second sequence. For example, the
equalalgorithm potentially compares every element from its first sequence to an element in the second. If the second sequence is a subset of the first, then our program has a serious error—equalwill attempt to access elements beyond the end of the second sequence.
fill(vec.begin(), vec.end(), 0); // reset each element to 0
// set a subsequence of the container to 10
fill(vec.begin(), vec.begin() + vec.size()/2, 10);
Because fill writes to its given input sequence, so long as we pass a valid input sequence, the writes will be safe.
Some algorithms take an iterator that denotes a separate destination. These algorithms assign new values to the elements of a sequence starting at the element denoted by the destination iterator. For example, the fill_n function takes a single iterator, a count, and a value. It assigns the given value to the specified number of elements starting at the element denoted to by the iterator. We might use fill_n to assign a new value to the elements in a vector:
vector<int> vec; // empty vector
// use vec giving it various values
fill_n(vec.begin(), vec.size(), 0); // reset all the elements of vec to 0
The fill_n function assumes that it is safe to write the specified number of elements. That is, for a call of the form
fill_n(dest, n, val)
fill_n assumes that dest refers to an element and that there are at least n elements in the sequence starting from dest.
It is a fairly common beginner mistake to call fill_n (or similar algorithms that write to elements) on a container that has no elements:
vector<int> vec; // empty vector
// disaster: attempts to write to ten (nonexistent) elements in vec
fill_n(vec.begin(), 10, 0);
This call to fill_n is a disaster. We specified that ten elements should be written, but there are no such elements—vec is empty. The result is undefined.
Algorithms that write to a destination iterator assume the destination is large enough to hold the number of elements being written.
back_inserterOne way to ensure that an algorithm has enough elements to hold the output is to use an insert iterator. An insert iterator is an iterator that adds elements to a container. Ordinarily, when we assign to a container element through an iterator, we assign to the element that iterator denotes. When we assign through an insert iterator, a new element equal to the right-hand value is added to the container.
We’ll have more to say about insert iterators in § 10.4.1 (p. 401). However, in order to illustrate how to use algorithms that write to a container, we will use back_inserter, which is a function defined in the iterator header.
back_inserter takes a reference to a container and returns an insert iterator bound to that container. When we assign through that iterator, the assignment calls push_back to add an element with the given value to the container:
vector<int> vec; // empty vector
auto it = back_inserter(vec); // assigning through it adds elements to vec
*it = 42; // vec now has one element with value 42
We frequently use back_inserter to create an iterator to use as the destination of an algorithm. For example:
vector<int> vec; // empty vector
// ok: back_inserter creates an insert iterator that adds elements to vec
fill_n(back_inserter(vec), 10, 0); // appends ten elements to vec
On each iteration, fill_n assigns to an element in the given sequence. Because we passed an iterator returned by back_inserter, each assignment will call push_back on vec. As a result, this call to fill_n adds ten elements to the end of vec, each of which has the value 0.
The copy algorithm is another example of an algorithm that writes to the elements of an output sequence denoted by a destination iterator. This algorithm takes three iterators. The first two denote an input range; the third denotes the beginning of the destination sequence. This algorithm copies elements from its input range into elements in the destination. It is essential that the destination passed to copy be at least as large as the input range.
As one example, we can use copy to copy one built-in array to another:
int a1[] = {0,1,2,3,4,5,6,7,8,9};
int a2[sizeof(a1)/sizeof(*a1)]; // a2 has the same size as a1
// ret points just past the last element copied into a2
auto ret = copy(begin(a1), end(a1), a2); // copy a1 into a2
Here we define an array named a2 and use sizeof to ensure that a2 has as many elements as the array a1 (§ 4.9, p. 157). We then call copy to copy a1 into a2. After the call to copy, the elements in both arrays have the same values.
The value returned by copy is the (incremented) value of its destination iterator. That is, ret will point just past the last element copied into a2.
Several algorithms provide so-called “copying” versions. These algorithms compute new element values, but instead of putting them back into their input sequence, the algorithms create a new sequence to contain the results.
For example, the replace algorithm reads a sequence and replaces every instance of a given value with another value. This algorithm takes four parameters: two iterators denoting the input range, and two values. It replaces each element that is equal to the first value with the second:
// replace any element with the value 0 with 42
replace(ilst.begin(), ilst.end(), 0, 42);
This call replaces all instances of 0 by 42. If we want to leave the original sequence unchanged, we can call replace_copy. That algorithm takes a third iterator argument denoting a destination in which to write the adjusted sequence:
// use back_inserter to grow destination as needed
replace_copy(ilst.cbegin(), ilst.cend(),
back_inserter(ivec), 0, 42);
After this call, ilst is unchanged, and ivec contains a copy of ilst with the exception that every element in ilst with the value 0 has the value 42 in ivec.
Some algorithms rearrange the order of elements within a container. An obvious example of such an algorithm is sort. A call to sort arranges the elements in the input range into sorted order using the element type’s < operator.
As an example, suppose we want to analyze the words used in a set of children’s stories. We’ll assume that we have a vector that holds the text of several stories. We’d like to reduce this vector so that each word appears only once, regardless of how many times that word appears in any of the given stories.
For purposes of illustration, we’ll use the following simple story as our input:
the quick red fox jumps over the slow red turtle
Given this input, our program should produce the following vector:
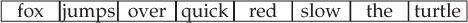
Exercises Section 10.2.2
Exercise 10.6: Using
fill_n, write a program to set a sequence ofintvalues to 0.Exercise 10.7: Determine if there are any errors in the following programs and, if so, correct the error(s):
(a)
vector<int> vec; list<int> lst; int i;
while (cin >> i)
lst.push_back(i);
copy(lst.cbegin(), lst.cend(), vec.begin());(b)
vector<int> vec;
vec.reserve(10); // reserve is covered in § 9.4 (p. 356)
fill_n(vec.begin(), 10, 0);Exercise 10.8: We said that algorithms do not change the size of the containers over which they operate. Why doesn’t the use of
back_inserterinvalidate this claim?
To eliminate the duplicated words, we will first sort the vector so that duplicated words appear adjacent to each other. Once the vector is sorted, we can use another library algorithm, named unique, to reorder the vector so that the unique elements appear in the first part of the vector. Because algorithms cannot do container operations, we’ll use the erase member of vector to actually remove the elements:
void elimDups(vector<string> &words)
{
// sort words alphabetically so we can find the duplicates
sort(words.begin(), words.end());
// unique reorders the input range so that each word appears once in the
// front portion of the range and returns an iterator one past the unique range
auto end_unique = unique(words.begin(), words.end());
// erase uses a vector operation to remove the nonunique elements
words.erase(end_unique, words.end());
}
The sort algorithm takes two iterators denoting the range of elements to sort. In this call, we sort the entire vector. After the call to sort, words is ordered as

Note that the words red and the appear twice.
uniqueOnce words is sorted, we want to keep only one copy of each word. The unique algorithm rearranges the input range to “eliminate” adjacent duplicated entries, and returns an iterator that denotes the end of the range of the unique values. After the call to unique, the vector holds

The size of words is unchanged; it still has ten elements. The order of those elements is changed—the adjacent duplicates have been “removed.” We put remove in quotes because unique doesn’t remove any elements. Instead, it overwrites adjacent duplicates so that the unique elements appear at the front of the sequence. The iterator returned by unique denotes one past the last unique element. The elements beyond that point still exist, but we don’t know what values they have.
The library algorithms operate on iterators, not containers. Therefore, an algorithm cannot (directly) add or remove elements.
To actually remove the unused elements, we must use a container operation, which we do in the call to erase (§ 9.3.3, p. 349). We erase the range of elements from the one to which end_unique refers through the end of words. After this call, words contains the eight unique words from the input.
It is worth noting that this call to erase would be safe even if words has no duplicated words. In that case, unique would return words.end(). Both arguments to erase would have the same value: words.end(). The fact that the iterators are equal would mean that the range passed to erase would be empty. Erasing an empty range has no effect, so our program is correct even if the input has no duplicates.
Exercises Section 10.2.3
Exercise 10.9: Implement your own version of
elimDups. Test your program by printing thevectorafter you read the input, after the call tounique, and after the call toerase.Exercise 10.10: Why do you think the algorithms don’t change the size of containers?
 Note
Note Best Practices
Best Practices Warning
Warning